
From now, LeakLooker supports Cassandra and Rethink databases and directory listing. It has been rewritten and uses completely new engine — Binaryedge.io. Article covers different types of leaks — targeted, mass and cloud. It also presents data you can find with help of the tool.
Notice: I’m not blaming or pointing fingers on any companies. My intent is not to make any reputation or financial damage to any company. At the end of the day we play for this same team.
 woj-ciech
woj-ciech
Introduction
There is almost no day without leak, breach or hack due to negligence or misconfiguration.. As previous parts of LeakLooker shows, one small mistake might lead to catastrophic failure and in some cases to total compromise of company data. Everyone probably knows ‘infamous’ culprits of leaks like ElasticSearch, MongoDB or Rsync protocol. Examples I will show proofs that there is still completely new territory to explore, every database or service wrongly configured can reveal sensitive information and sometimes grants you permission to write and execute, which means you can tamper with data, encrypt it and demand a ransom. I’m aware of ransom campaigns against Mongo, ElasticSearh or Redis but also I came across some ‘ransomed’ RethinkDB. This trend won’t stop and will only get worse, so act before someone else will do it for you.
For researchers it’s a great way to take a look what is behind the curtain i.e. what information companies store, in what way and if it’s consistent with their privacy policy. After playing a little with LL, you can draw conclusion that most of the institutions, from startups to big corporate, don’t often takes proper steps to secure their assets. Even test environments can give great insight about company policy and as you will see, these environments are very poorly configured and just wait to be discovered.
This version of LeakLooker operates as previous ones but it uses new engine — binaryedge.io. It’s super flexible, supports many filters and gives great results. Shodan version won’t be supported anymore.
This update adds also three new services — Cassandra and Rethink databases and listing directory with following filters:
- “Index of /” for listing directory
- type:”cassandra” for Cassandra database
- type:”rethinkdb” for Rethink database
and everything is colored for easier navigation.
Targeted vs Mass vs Cloud
Personally, I distinguish three types of leaks:
- Targeted — when one looks for information related to specific organization or company. It is based on keywords, Autonomus System Numbers (ASN) or IP addresses. For example, “Pfizer” owns ASN 7068 (data from bgp.he.net), so to search their “property”, you need to pass additional custom argument to the tool ‘— query “asn:7068”’ with type of leak you want to search. Adequately, it’s possible to search in CIDR ‘ — query “ip:170.116.64.0/21”’ or country ‘— query “country:SL”’. Full list of supported query parameters is here
- Mass — when one looks for any sensitive, valuable information no matter of institution. Mostly, it is used along with free text search with variety of keywords depending of the searched data. For medical institutions it can be ‘patients’, ‘doctors’, ‘medical’ or ‘hospital’. List is almost infinity if we take into account different drugs or disease that might be used as a table or keyspace in database.
- Cloud — it’s very similar to Mass scan however in this case it’s hard to find responsible person or security contact. Sometimes it can be deducted from gathered data inside of the database, however it’s not always that simple. This kind of search is time consuming because it does not always depend of the keywords. It’s hard to predict every possible name for table in database and even someone would, files can be kept in completely impossible to foresee directory, example: S3 bucket with name “tppcf” https://www.upguard.com/breaches/amazon-s3-how-tea-party-campaign-assets-were-exposed-online or “pinapp2” https://www.upguard.com/breaches/out-of-pocket-how-an-isp-exposed-administrative-system-credentials
Listing directory
It may sounds funny to look for leaks in servers with directory listing enabled and I haven’t seen any critical mistake in this behavior until I came across server which belongs to TimiHealth.
It often happens that directory listing is enabled on test servers for easier managing and navigation but when unsecured, creates opportunity to move within and download files without need to know or bruteforce paths.
The most interesting files were in ‘uploads/patients-dna-uploads/’ and ‘/patients-uploads’. First one contained around 10k directories (~90% were useless) with push notification logs, couple files with plaintext emails and passwords, QR codes, magnum wallets backups and DNA samples, everything in text format. Second directory revealed photos of different prescriptions and medical tests, probably uploaded by users. Navigation in the server was hard, because every document was in separate directory, it was just a mess like it happens on test environments. It is worth to mention that server was live because it was creating new directories with logs in specific time periods.



As you see above, it is highly personal and confidential but personally it tells me nothing. I have no idea about DNA structure and results from examination so I cannot confirm authenticity of data. We need to wait for official public response from company if there will be any. According their tweets, it was small test group of 14 people, only friends and family of developers.
I heard about breach of MyHeritage breach however only usernames and hashed password have been compromised, no information about DNA, so it might be first leak of someone’s DNA in digital form, if company will confirm.
Unfortunately, I’ve got no response to my emails from them at that time but exposed information were really sensitive.
Rethink DB
Rethink is an open source and document oriented database, which uses JSON format. As mentioned at the beginning, RethinkDB can give full permissions, which results in compromise of DB it’s not a trend yet to encrypt Rethink databases but as criminals look for new methods, it can be their next target.
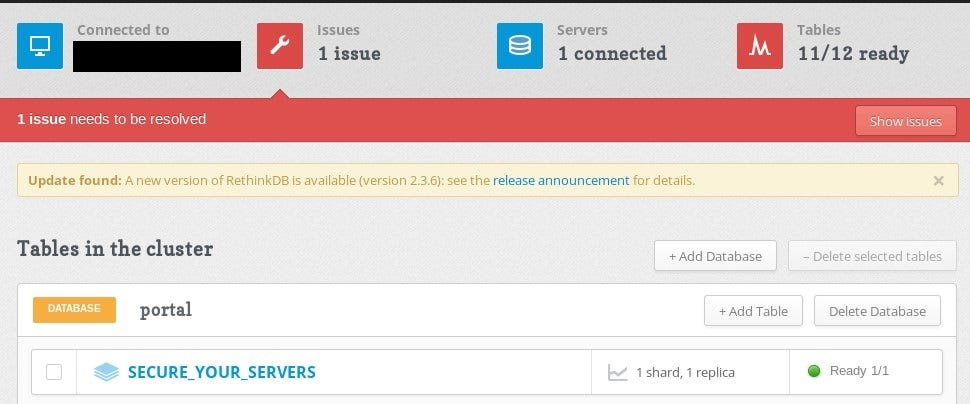
In this case only additional empty table “SECURE_YOUR_SERVERS” has been added but it could go much worse than that.
Usually it uses port 28015 for client driver port and port 8080 as admin GUI. In addition it has it’s own query language called ReQL and what I really like is that it is chainable. Data explorer, gives access to console where one can query database and tables.

Another interesting things exposed by Rethink are statistics and logs, you can get insight who accessed what at what time or server specifications like operating system, cache size or up-time.

Gitlab still leaks
Intellectual property is one of the most valuable thing for company, you could read about Cambrigde Analytica leaks in UpGuard breaches. I’m aware about ransomware campaign against Git services but this method is completely different. It’s not necessary to to scan for “.git” files when you just can register yourself.
I decided to check by myself how damaging this kind of leak might be for organization. It didn’t take long, when I came across on Gitlab instance of company X. Because of sensitivity of data and potential deterioration of relations with clients, I didn’t get permission to name the company. No customer would be happy knowing their data is not secure.
Their Gitlab allowed registration from any email address and gives permission, like you would work there, i.e. access to internal resources, application source code, projects or configuration files.
Config files are one of the first things attacker would look for to escalate his privileges and get access to even more data that’s not stored in Gitlab. Next one would be internal resources — handbooks, guides and tutorials to understand internal infrastructure and projects. It’s technique used by Advanced Persistent Threat (APT) actors to study network and internal information for easier movement, which results harder detection.
I saw files that was edited less than hour ago, at that time, which implies that server was in use and it was production.
In this case ransomware is also an option and it’s going worse when you work for other customers and you put them in danger too.
In case of reporting, completely different behavior was presented by X. It took about 2 hours from my initial email to secure the server. After sending information to the support about the issue, I was contacted by X’s CEO and open registration has been closed and probably some investigation started.
Reporting
Reporting it’s the hardest thing in this party. Companies often does not provide security contacts or to someone technical who can help. Chats on the sites are just totally pointless, time wasting and support usually answer after couple days. Below you can find couple advises that will make life easier for researchers and companies.
- Open Twitter DMs. Lot of researchers use Twitter and DM to the company official account would be one of the fastest way to reach someone. Given that someone actually manage the account. In both cases — Timihealth and X, DMs were not allowed.
- Put security.txt in your website. It’s small text file similar to robots.txt, which defines security contacts inside organisation — https://securitytxt.org/
- Bug bounty. You don’t have to go to HackerOne or Bugcrowd to create bug bounty program and especially if you are not big corporation. It happened once that I found a vulnerability by accident and to my surprise they had a small bug bounty program, which makes life easier. https://unsplash.com/security
- It happened. Don’t blame researchers or look for fault anywhere. It happened and the best what you can do is to secure the server as fast as possible. It’s not shame and companies can even make profit from PR perspective giving small gift. It cost nothing but looks better in eyes of community.
Conclusion
After playing with LeakLooker you will see that described cases are only drop in the ocean of the data. It’s bad and will only get worse but I strongly believe there are still good people out there that care about securing digital world, and don’t bother about financial profits from their activity.
Originally published on 9th of August, 2019
 Wojciech
WojciechPlease subscribe for early access, new awesome things and more.